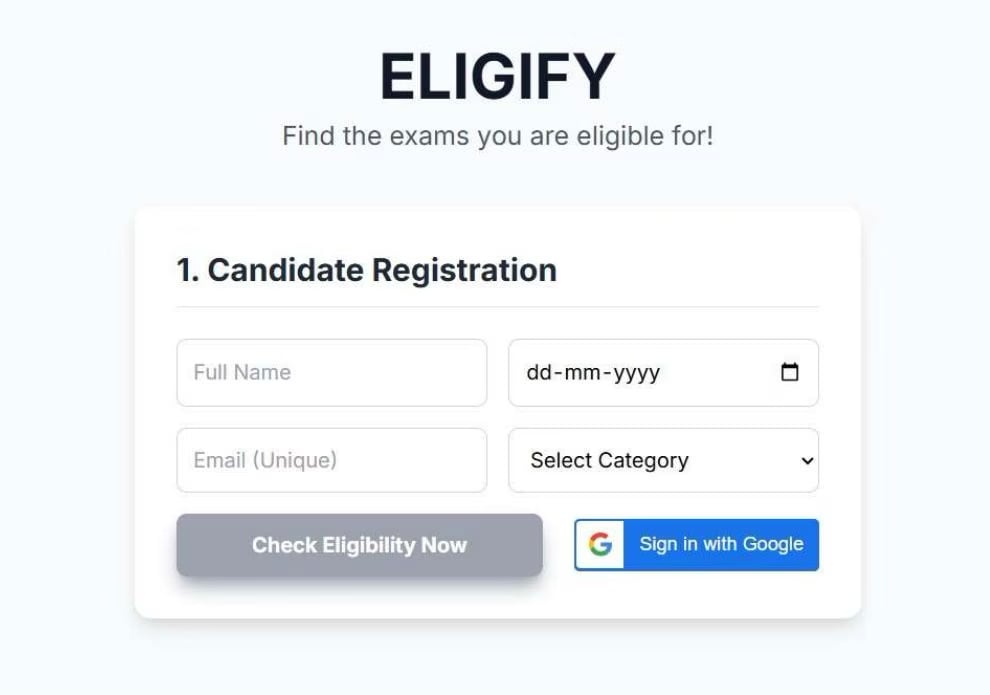
Eligify
A secure exam eligibility verification system with hybrid document parsing that automates student data cross-referencing against exam rules.
Problem
Indian students applying for competitive exams — JEE, GATE, UPSC, NEET — face two manual problems:
-
Eligibility discovery: Every exam has different age limits, 10th/12th percentage thresholds, and UG CGPA cutoffs. Students manually cross-check each exam's brochure. With 20+ major exams, this is slow and error-prone.
-
Credential verification: Application forms require exact percentage or CGPA values. Students read these off marksheets by hand, and errors lead to form rejection.
Neither problem requires ML — both are solvable with deterministic rules and document parsing, which shaped the architecture.
Solution
Two independent functions:
-
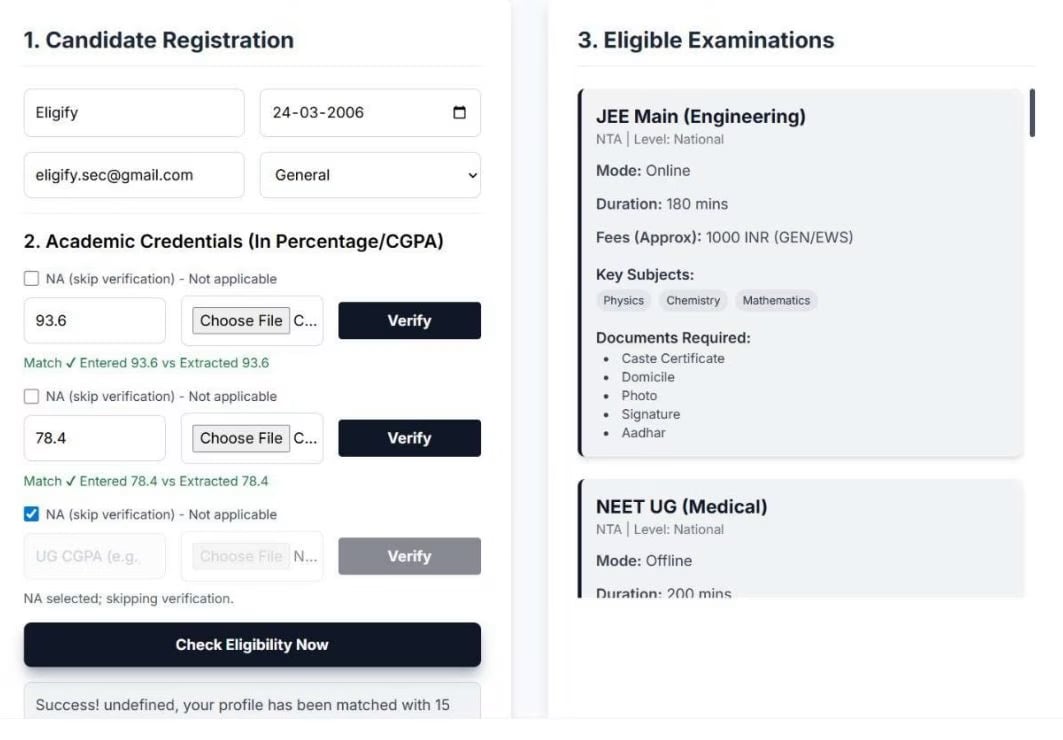
Eligibility Engine: Takes candidate age, 10th %, 12th %, and UG CGPA. Runs a rule-based check against every exam's criteria and returns the eligible subset.
-
Document Parser and Verifier: Accepts a marksheet PDF or image. Extracts the text layer; falls back to Tesseract OCR if absent. Parses the text with regex to locate percentage, CGPA, and subject marks. The verify endpoint compares the parsed value against the student's entered value and returns a boolean with the difference.
Both are exposed via a REST API. The frontend is a single server-rendered HTML page with vanilla JS.
Key Features
| Feature | Description |
|---|---|
| Eligibility check | Rule-based check across age, 10th %, 12th %, UG CGPA against 20 exam records |
| Auto-method extraction | PyPDF2 text layer first; Tesseract OCR fallback if text < 20 characters |
| Image preprocessing | 5-variant pipeline: grayscale, median blur, Gaussian blur, bilateral filter, adaptive threshold |
| CGPA table parsing | Column-index detection for CGPA in semesterwise tables (pipe and whitespace-separated) |
| Academic verification | Extracted value compared to entered value within configurable tolerance (default ±0.1) |
| Google OAuth | Server-side ID token verification via google-auth; user upserted to DB on login |
| Rate limiting | In-memory sliding-window: 50 req/min for parse, 30 req/min for verify |
| Security headers | CSP, HSTS, X-Frame-Options, X-Content-Type-Options, Referrer-Policy on every response |
| File validation | Extension allowlist (pdf, png, jpg, jpeg), 10 MB cap, empty file rejection |
Tech Stack
Flask — small API surface (5 endpoints), no async or admin needs. Blueprints separate the web, API, and auth controllers cleanly. Django would have added unused ORM, admin, and form scaffolding.
SQLAlchemy — ORM that switches between SQLite and PostgreSQL by changing DATABASE_URL. Maps to five tables: users, candidate_profiles, document_uploads, parsed_documents, academic_verifications.
SQLite (default) — Exam data lives in ExamRepository as a Python list of dataclass instances, not in the DB. 20 records, no joins needed, no round-trip overhead.
google-auth — id_token.verify_oauth2_token fetches Google's public keys and verifies the JWT signature, audience, and expiry in one call.
PyPDF2 — extracts the embedded text layer directly from a PDF without rendering. Faster and more accurate than OCR for Digilocker-issued marksheets, which contain selectable text.
pdf2image + Poppler — converts PDF pages to raster images when the text layer is absent or insufficient. pdf2image wraps Poppler's pdftoppm. Used instead of PyMuPDF because Poppler is more widely packaged and the dependency chain for pdf2image is simpler.
pytesseract — Python wrapper for Tesseract OCR. Uses --psm 6 (uniform text block) as the primary mode; for image inputs cycles through --psm 4, --psm 11, and --oem 1 --psm 6 across all preprocessed variants.
Pillow — grayscale conversion, resize to minimum 1200px, autocontrast, median filter, Gaussian blur, inversion. Used when OpenCV is unavailable.
OpenCV — more capable preprocessing when available: medianBlur, GaussianBlur, bilateralFilter, and adaptive Gaussian thresholding (adaptiveThreshold(Gaussian, 35, 11)). Adaptive thresholding handles uneven lighting by computing a local threshold per 35×35 pixel window rather than a single global value.
Tailwind CSS via CDN — no build step, single HTML template.
Vanilla JS ES modules (static/js) — views/ renders DOM, models/ holds data structures, services/ calls the API, utils/ holds shared helpers. No bundler needed for a form plus a results list.
Technical Architecture
Browser
│
│ GET / → templates/index.html (Jinja2)
│ POST /auth/google → verify Google token, upsert User, set session
│ GET /api/exams → ExamRepository list (in-memory)
│ POST /api/candidate-profile → save CandidateProfile to DB
│ POST /api/parse-marksheet → validate → parse PDF/image → return fields
│ POST /api/verify-academic → validate → parse → compare → save result
│
▼
Flask app (app.py)
├── Blueprint: web_controller (GET /)
├── Blueprint: auth_controller (GET /login, POST /auth/google, POST /logout)
└── Blueprint: api_controller (all /api/* routes)
│
├── middleware/security.py
│ validate_file_upload() → extension, size, empty-file checks
│ validate_dpi() → clamps 100–600
│ validate_method() → 'auto' | 'text' | 'ocr'
│ sanitize_input() → strip null bytes, control chars, truncate
│ rate_limit(n, window) → in-memory sliding-window per IP
│ setup_security_headers() → CSP, HSTS, X-Frame-Options, etc.
│
├── lib/pdf_parser.py
│ parse_pdf()
│ 1. _configure_tesseract_from_env() → read TESSERACT_CMD env var
│ 2. _extract_text_layer() via PyPDF2
│ if text_layer >= 20 chars → return text
│ 3. _is_ocr_available() → check Poppler + Tesseract on disk
│ 4. _images_from_input() → pdf2image / Poppler at given DPI
│ 5. img.convert("L") → pytesseract(--psm 6)
│
│ extract_marksheet_fields_from_image()
│ → _variants(img): 5 preprocessing variants
│ Pillow: grayscale, autocontrast, resize, median, gaussian, invert
│ OpenCV: grayscale, resize, medianBlur, GaussianBlur,
│ bilateralFilter, adaptiveThreshold(Gaussian,35,11)
│ → pytesseract × 4 PSM configs per variant
│ → _parse_marksheet_text(merged_output)
│
│ _parse_marksheet_text(text)
│ → NFKC Unicode normalisation
│ → regex: name, roll_no, DOB, exam, year, university, college
│ → extract_cgpa_from_table(): column-index detection
│ → subject line regex: "Subject Name marks/max grade"
│ → fallback: CGPA×9.5, or total/max×100
│
└── services/
db.py → SQLAlchemy engine + scoped_session + init_db()
exam_repository.py → in-memory list of 20 Exam dataclass instances
eligibility_service.py → calls Exam.is_eligible(candidate) on each
SQLAlchemy Models (models/db_models.py)
users sub(PK), email, name, picture, created_at
candidate_profiles id, user_sub(FK), first_name, dob, category, p10, p12, ug_cgpa
document_uploads id, user_sub(FK), doc_type, filename, mime, stored_path, uploaded_at
parsed_documents id, upload_id(FK), parsed_json, created_at
academic_verifications id, user_sub(FK), stage, entered_value, extracted_value,
verified, upload_id(FK), filename, mime, created_at
eligibility_checks id, candidate_id(FK), exam_id(FK), eligible, run_at,
inputs_snapshot [unique: candidate_id + exam_id]
/api/verify-academic request flow
- Rate limit check (30/min per IP).
validate_file_upload: extension in{pdf,png,jpg,jpeg}, size ≤ 10 MB, not empty.validate_method,validate_dpion query params.- Detect file type by MIME and extension.
- If image →
extract_marksheet_fields_from_image(5 variants × 4 PSM configs). - If PDF →
extract_marksheet_fields(text layer first, OCR fallback). - Pull
percentageorcgpabased onstage(10/12→ percentage,UG→ CGPA). - If value missing or diff > tolerance: re-run forced
method='ocr'at DPI ≥ 300. - Compare to user-entered value within tolerance (default 0.1).
- Persist
DocumentUpload→ParsedDocument→AcademicVerification. - Return
{stage, entered, extracted, difference, tolerance, comparison_source, verified, fields}.
Problems Faced
1. Tesseract and Poppler binary resolution on Windows
pytesseract shells out to the Tesseract C++ binary via subprocess — it does not install through pip. pdf2image wraps Poppler's pdftoppm, also a C binary. On Windows, neither is on PATH by default. If either path is wrong, the subprocess call silently fails or raises an unhelpful FileNotFoundError.
Solution: Layered path resolution in _configure_tesseract_from_env() and _detect_poppler_path():
- Tesseract: read
TESSERACT_CMDenv var → check defaultC:\Program Files\Tesseract-OCR\tesseract.exe. - Poppler: read
POPPLER_PATHenv var →shutil.which("pdftoppm")parent dir → walk%LOCALAPPDATA%\Microsoft\WinGet\Packagesforpdftoppm.exe.
_is_ocr_available() checks both binaries on disk before any OCR call and returns a descriptive error if either is missing. pytesseract and pdf2image imports are wrapped in try/except so all non-OCR endpoints work even if prerequisites are not installed.
2. Non-standard marksheet formats
CBSE 12th prints Percentage: 85.4%. A university marksheet has a SEM | TTCR | TTCP | SGPA | CGPA | RESULT table with the cumulative CGPA in the last data row. A state board certificate labels it Total Marks Obtained with no percentage field. A single regex pattern cannot cover all three.
Solution: _parse_marksheet_text tries five methods in order, accepting the first non-null result:
- Regex on
Percentage: NN.NNlabels. - Regex on
CGPA: N.NNlabels. extract_cgpa_from_table()— detects CGPA column index from the header row, reads numeric values from that index in subsequent rows, returns the last (cumulative). Fallback: scans pipe-separated rows with ≥ 3 numeric columns and reads values in the 0–10 range from columns 3+.- Regex on
Total Marks / Grand Totalwith optional max-marks group; computestotal / max × 100. - Sums subject-level marks from the subject-line regex, divides by
100 × subject_count.
CGPA-to-percentage: CGPA × 9.5 (UGC standard).
3. OCR quality on phone photos
A single grayscale conversion with one PSM mode produces poor results on photos with uneven lighting or thin table borders.
Solution: 5 preprocessing variants per image, each run through 4 PSM configs (--psm 6, --psm 4, --psm 11, --oem 1 --psm 6). All non-empty outputs are concatenated and passed to _parse_marksheet_text. The regex anchors on field labels, so duplicate text from multiple variants is harmless — it only increases the chance that at least one variant produced a readable result per field.
OpenCV preprocessing (when available): medianBlur → GaussianBlur → bilateralFilter → adaptiveThreshold(ADAPTIVE_THRESH_GAUSSIAN_C, THRESH_BINARY, 35, 11). The adaptive threshold computes a local binarisation threshold per 35×35 pixel window, which handles uneven lighting that a global threshold cannot.
Images are upscaled to a minimum of 1200px on the longest side before OCR — ~300 DPI equivalent for A4, which is Tesseract's target resolution.
4. Unicode inconsistencies in PDF text layers
PDFs from different generators encode the same characters differently. \u2013 (en-dash) where a hyphen was expected, \u00A0 (non-breaking space) breaking word-boundary matches, and ligatures in OCR output all caused regex patterns to fail silently.
Solution: _normalize(s) runs unicodedata.normalize('NFKC', s) to decompose ligatures and compatibility forms, then explicitly replaces \u2013/\u2014/\u2212 → -, \u00A0/\u2009 → space, \u2026 → ..., and \s+/\s+ → /. The separator pattern sep = r"[:\-–—]" matches remaining variants. This runs before any regex so all downstream patterns operate on a consistent string.
5. Flask has no built-in input validation, rate limiting, or security headers
Without adding these, the upload endpoint accepts any file size and type, OCR can be called in a tight loop, and text extracted from documents can be reflected to the browser unsanitised.
Solution (middleware/security.py):
- File validation:
filename.rsplit('.', 1)[1]against an allowlist;file.seek(0, SEEK_END)to compute size without buffering the full file; FlaskMAX_CONTENT_LENGTH = 10MBtriggers a 413 before the view function runs. - Rate limiting: each decorated endpoint gets a
defaultdict(list)keyed byrequest.remote_addr; timestamps outside the window are evicted; returns 429 if count ≥ limit. In-memory per-process — a known limitation noted in the code. - Output sanitisation: strips
\x00–\x08,\x0B–\x0C,\x0E–\x1F,\x7Ffrom all strings before they enter a JSON response. - Security headers: applied in
app.after_requestto every response. CSP restricts scripts toself, Tailwind CDN, andaccounts.google.com. HSTS set for 1 year.
Impact
- Eligibility check across 20 exams: from ~2 hours of manual brochure-reading to under 30 seconds.
- Marksheet parsing eliminates manual percentage/CGPA transcription errors at form-filling.
- The verify endpoint gives students a document-backed confirmation of the value they are entering, with a ±0.1 tolerance to account for rounding differences.
- The text-layer + OCR fallback covers both Digilocker-generated PDFs and scanned documents.
Future Improvements
- Exam data in DB:
ExamRepositoryis a hardcoded list. Criteria change yearly; a DB table with an admin interface removes the need for a code deploy on each update. - Redis for rate limiting: The in-memory limiter resets on restart and does not work across multiple workers.
- File storage:
DocumentUpload.stored_pathis alwaysNone. Storing the file or a hash would allow re-parsing without re-upload. - Confidence scoring:
pytesseract.image_to_datareturns per-character confidence. Returning a parse confidence score would let the frontend warn users when OCR output is likely unreliable.
Snapshots